Introduction
Basic medical education curricula often utilize cut-off scores in multiple-choice examinations to gauge whether students have achieved their learning goals [1-3]. Although it is recommended not to use arbitrary passing scores in education, medical schools still use arbitrary cutoffs to determine passing scores [3]. Medical students at our institution must score 70% or more on tests to pass courses. For practical reasons, it is costly and infeasible for content experts to examine all items and to determine minimum levels of achievement [4], since courses are taught by teams of experts and assessments are made via several tests administered throughout each course. Therefore, when students score 70% or more on tests in any course, which is generally equivalent to a grade of C, they are considered to have achieved their learning goals in the course.
In addition to setting standards arbitrarily, what are considered passing scores are fixed over the years at some medical education institutions [2,5]. In a previous study of a licensing exam, the use of fixed passing scores was found to potentially cause problems associated with pass/fail decisions [6]. If a test in a given year was significantly easier than in past years, examinees could earn high scores and pass the test even though they do not achieve the expected level. Another study found that test difficulty was related to variation in examinees’ failure rates when pre-fixed cut-off scores were used [4]. The disadvantages of fixed passing scores indicate a need to adjust passing scores to ensure that they are equivalent to those of previous terms through the process of test equating.
In this study, we applied test equating based on item response theory (IRT) [7], in which a unique item characteristic curve (ICC) is determined for each item to indicate the probability that an examinee with specific ability will respond correctly to the item. Mathematical models of IRT may be used to express item difficulty, discrimination, and guessing parameters on ICCs. Item difficulty (‘b’) is a corresponding ability parameter defined when the probability of a correct response is 0.5. Item discrimination (‘a’) is defined as the ICC slope when the probability of a correct response to the item is 0.5. Item guessing parameter (‘c’) is the probability that an examinee with no ability will answer the item correctly. One-parameter models, or Rasch models, calculate only item difficulty. Two-parameter models add item discrimination to determinations of item difficulty. Three-parameter models add an item guessing parameter to item difficulty and discrimination.
The principal advantage of IRT is the invariance of item and ability parameters [8,9]. In other words, item parameters are not dependent on examinees’ abilities, and ability parameters are not dependent on item parameters if the IRT model shows good model-data fit and meets the assumptions of unidimensionality and local independence. The assumption of invariance is valid when items and ability parameters are represented by the same ability scale [7]. Thus, the ability parameter of a student may be different if tests they took are calibrated using different ability scales.
Test equating locates two tests on a common ability scale so that the scores of the tests can be interchangeably compared. Test equating is required to compare different forms of tests. Putting two tests (X and Y) on the same ability scale requires linear transformation of ability (θ) as shown below [10].
A and B are equating coefficients in a linear equation (1). Relationships of item parameters of two tests are as follows:
Methods used for calculating equating coefficients in IRT include mean/mean, mean/sigma, and characteristic curve methods [6,10].
Until now, test equating based on IRT has been used in medical education mostly for high-stakes examinations or to equalize two tests given in the same course [6,11,12]. Yim and Huh [6] equated the 2004 Medical Licensing Examination in Korea to the 2003 exam, identified changes of item and ability parameters between the tests, and judged the equity of passing scores between them. Two other studies performed test equating for two tests given in the same course over 2 years [11,12]. However, to the best of our knowledge, few researchers have attempted to equate all of the tests given in courses that are part of a basic medical education curriculum.
Using fixed cutoffs to determine passing scores requires that the item and ability parameters of tests remain constant year after year. In order to investigate the validity of using fixed passing scores in this manner, we examined whether there were significant differences in items according to year after performing test equating. We also identified gaps between scores equated to previous passing scores and actual passing scores in subsequent tests. The aim of this study was to equate in-house computer-based test (CBT) results accumulated in our basic medical education curriculum, to test change of item difficulty distributions, and to verify that passing scores of previous and subsequent years were equivalent.
Methods
The equating design used in this research was non-equivalent groups with common items, a method that is generally used in test equating [10], because our examinee groups were not equivalent by year, and common items were used in the tests. The common items included in this study were the same for clinical vignettes, lead-in questions, keys, and distractors.
1. Objects of study
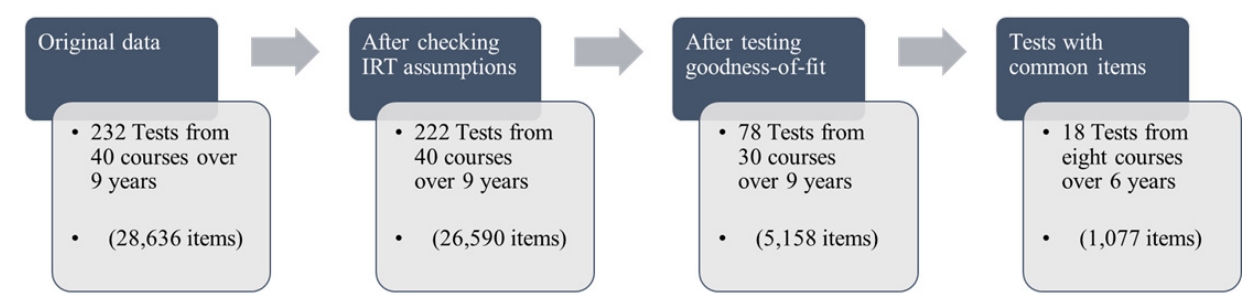
The data used for test equating were selected from CBT results from the basic medical education curriculum from 2009 to 2017 at the College of Medicine, the Catholic University of Korea. We included only multiple-choice tests. The CBT results were presented as a matrix consisting of examinees and items. Test results for 28,636 items were coded as 0s or 1s. We divided the matrix into courses, and then split the data in each course by year. The final data used for test equating were 12 pairs of tests that were administered in eight courses (Table 1). We describe how the final data were selected in the ‘procedure’ section (Fig. 1).
2. Procedure
We decided to fit our whole dataset to a Rasch model because of the small sample size [8]. First, assumptions were checked for 232 Rasch models for the 40 courses. CBT results for a year in a course became one Rasch model, which was referred to as ‘a test’ in this paper. We confirmed unidimensionality, using the unidimTest function in R package ltm, which performs a procedure that analyzes the latent dimensionality of dichotomous responses [13]. The assumption of local independence indicates that a response to an item is independent of any response to other items [8]. According to a previous study, when the criterion of unidimensionality was met, the assumption of local independence was considered to be satisfied [14]. Next, we tested model-data fit. After excluding 10 tests that did not meet the criterion of unidimensionality, we assessed goodness-of-fit for 222 tests, using the GoF function in ltm, which was based on Pearson’s chi- square [13]. A total of 78 tests showed goodness-of-fit. Out of these, 12 pairs of tests with common items (18 tests) were finally analyzed for test equating (Table 1, Fig. 1).
3. Analysis
For every 12 pairs, we estimated equating coefficients for re-scaling using Stocking and Lord’s characteristic curve method which is known to give stable results [15]. After transforming a scale of a subsequent test to that of a previous test in each pair, item difficulty parameters were extracted from the two tests. We extracted both original item difficulty parameters and converted ones using the itm function in the R package equateIRT [16]. To examine whether difficulty parameters of common items, the other items, and all items significantly changed by year, we conducted Wilcoxon rank-sum tests.
Then, observed-scores in each pair were equated using an observed-score equating method. We used the score function in the package equateIRT [16]. We identified gaps between scores that were equated to previous passing scores and actual passing scores (70%) in subsequent tests. In this paper, we used the term ‘equated passing score’ to refer to a score that was equated to a previous passing score.
We used the R software package ver. 3.5.0 (https://cran.r-project.org/bin/windows/base) to perform test equating and estimate item difficulty. The level of significance for all analyses was set at p<0.05. The Institutional Review Board of the College of Medicine, the Catholic University of Korea approved the study protocol (IRB approval no., MC15EISI0121).
Results
1. Equating coefficients
In each pair, scales of subsequent tests were converted to those of previous tests. Because item discrimination parameters are all set to one in Rasch models [7], only equating coefficient Bs were reported. The equating coefficient Bs and standard errors for each pair were as follows. The equating coefficient B for anatomy II was 0.8658 (standard error [SE]=0.2033). Equating coefficient Bs for medical terminology in 2010 and 2011, in 2010 and 2012, and in 2011 and 2012 were 0.3102 (SE=0.2871), -0.1468 (SE=0.2686), and -0.2784 (SE=0.2457), respectively. The equating coefficient B for physiology was 1.3568 (SE=0.2628), for epidemiology 2.6354 (SE=0.3146), for hematology & oncology 2.3077 (SE=0.2978), for gastroenterology I 1.4301 (SE=0.1027), and for evidence-based medicine II 1.4814 (SE=0.3418), respectively. Finally, equating coefficient Bs for personalized medicine in 2012 and 2014, in 2012 and 2015, and in 2014 and 2015 were 2.0605 (SE=0.3646), 1.6216 (SE=0.2623), and 0.2147 (SE=0.2331), respectively.
2. Differences in item difficulty by year
Wilcoxon rank-sum tests revealed that two tests out of seven pairs did not have significantly different distributions for item difficulty (Table 2). The seven pairs were medical terminology (2010 and 2011; 2010 and 2012; 2011 and 2012), physiology, evidence-based medicine II, and personalized medicine (2012 and 2015; 2014 and 2015).
In contrast, two tests among the other five pairs showed significantly different distributions for item difficulty. Wilcoxon rank-sum tests showed that items in test 2015 in anatomy II were more difficult than those in test 2014 (median: -1.0625 versus -2.1164; W=1,504; p<0.05). The same pattern held true for epidemiology; test items in 2014 were more difficult than those in 2013 (median: 0.6047 versus -1.7453; W=118; p<0.05). In hematology & oncology, items in test 2014 were more difficult than those in test 2013 (median: 0.5515 versus -1.3778; W=1,529; p<0.05). In gastroenterology I, test items in 2014 were harder than those in 2013 (median: -0.1521 versus -1.5687; W=10,814; p<0.05). In personalized medicine, items in test 2014 were more difficult than those in test 2012 (median: 0.1151 versus -1.0863; W=135; p<0.05). For five pairs, items in subsequent tests were significantly more difficult than those in previous tests. In addition, the other items’ difficulties became harder in subsequent tests than in previous tests at p<0.05 (Table 2).
3. Gaps between equated passing scores and actual passing scores in subsequent tests
After test equating, scores of subsequent tests using scales of previous tests were transformed. Then, we compared gaps between actual passing scores of subsequent tests and the equated passing scores (Table 3). Among 10 pairs, the equated passing scores were lower than the actual passing scores. In anatomy II, the gap between an equated score for the 2015 tests and an actual passing score in 2015 was -20.3; the equated passing score for the 2015 test was 46.7% of the total score. The gaps for medical terminology in 2010 and 2011, in 2010 and 2012, and in 2011 and 2012 were -1.5, -2.5 and -0.2, respectively. The equated passing scores were 60.6%, 62.4%, and 69.4% of the total scores. In physiology, the gap was -4 (51.0%); in epidemiology, the gap was -7.3 (36.8%); in hematology & oncology, the gap was -37.5 (33.2%); and in gastroenterology I, the gap was -57.8 (44.5%). Gaps for personalized medicine in 2012 and 2014, and in 2012 and 2015 were -4.7 (46.5%) and -3 (59.7%), respectively. The range of gaps for the 10 pairs was -57.8 to -0.2.
In contrast, the equated passing scores were higher than actual passing scores in two pairs. In evidence-based medicine II, the gap was +0.2 (71.4%), and the gap for personalized medicine in 2014 and 2015 was +1.1 (73.8%).
Discussion
In this study, we performed test equating using CBT results for a basic medical education curriculum. We examined whether item difficulty distributions in 12 pairs of tests varied significantly by year, and investigated gaps between equated passing scores and actual passing scores. The implications of our findings are as follows.
First, it was found that items for subsequent tests were significantly more difficult than those of previous tests for five pairs. Changes in item difficulty distribution over the years is consistent with previous research results for a national examination [6] and a course’s two tests [11]. Since we investigated only 12 pairs of tests, it is cautious to generalize our results, but they demonstrate the possibility that significant differences may occur between item difficulties according to year. The significant change in item difficulty can confuse students as they prepare for tests. It implies that examiners need to set comparable items each year.
One thing notable is that the other items in the five pairs also became harder in subsequent years. These results differed from a previous study that found no significant difference between the other items over two years [12]. It is difficult to present the reason for the increase in the other items’ difficulty in this study. Given the possibility that information about previous test items is passed on to junior students by senior students in Korea [17], examiners may write more difficult items for in subsequent tests [18]. Alternatively, common items that are made easier by item disclosure may have caused biases in item difficulties [11,18]. Before test equating, the difficulties of common items between two tests are expected to be similar [19]. In this study, however, common items among the four pairs of tests were significantly easier in subsequent tests than in previous tests (Table 4). The easier common items in subsequent tests could have biased the difficulty of the other items by equating. Indeed, the difficulties of the other items in subsequent tests became significantly harder than before in the four pairs of tests (Table 4). The effect of item disclosure on test equating should be investigated in future studies.
Second, the equated passing scores were found to be lower than actual passing scores in 10 pairs. This may be because items on subsequent tests were harder than those on previous tests. For the five courses in which items became harder, the equated passing scores were less than 70% of the total score. The equated passing scores ranged from 33.2% to 69.4% of the total scores. Our results imply that examinees who took later tests may not have passed, even if they had scores equal to or higher than passing scores in previous years. Taking anatomy II as an example, the passing score for 2015 should be lower because test items in 2015 were more difficult than in 2014. That is, the passing score would have to be 40.6 to be equivalent to the previous passing score (Table 3). However, the passing score for 2015 was 60.9, which was 70% of the total score. This indicates that if some examinees scored higher than 40.6 but less than 60.9 in 2015, they would have passed in 2014, but did not in 2015. Gaps were also found in pairs where item difficulty distributions did not show significant differences by year: medical terminology in 2010 and 2011, in 2010 and 2012, in 2011 and 2012; physiology, evidence-based medicine II; personalized medicine in 2012 and 2015, in 2014 and 2015 (Tables 2, 3). Apart from the remaining item difficulty being constant across tests, our results demonstrate the need for equating passing scores, and confirm previous findings that gaps affect pass/fail decisions [6]. Notably, equating passing scores is a practical task for medical students because passing or failing tests has significant effects on grade promotion.
A limitation of this study is that we examined only a small number of common items for some pairs. In five pairs (hematology & oncology, gastroenterology I, evidence-based medicine II, and personalized medicine in 2012 and 2014, and in 2012 and 2015), common items were less than 20% of the entire test (Table 1). The small percentage of common items could have caused increased random equating errors. This may be due to items or examinees being excluded for computational reasons, or many common items being avoided in the courses. The results for these five pairs thus need to be interpreted with caution.
The reason for the reduced data included in our analyses is that we excluded tests that did not meet criteria for applying IRT (Fig. 1). In particular, many tests were not included because of poor fits between the Rasch models and data. Some common items decreased or disappeared after excluding rows or columns coded as only 0s or 1s. For data reduction, it is important to take into account the context of this study, which evaluated several tests from a medical school, rather than a national exam. This source of data reduction may lead to difficulty in applying in-house tests to IRT and performing test equating in future studies.
In this research, we tried to equate in-house tests from a basic medical education curriculum. Based on these findings, we propose methods to ensure that tests are implemented consistently every year. First, items should have similar difficulty indices in different terms. Selecting items with similar difficulty from an item bank could make this possible. Second, passing scores could be equated to previous scores each year.